What Is Multimodal Learning? A Simple Guide to How AI Sees, Hears, and Reads
multimodal learningai modelsmachine learningdata fusion
October 2, 2025
20 min read
At its heart, multimodal learning is all about teaching AI to understand the world a lot more like we do—by using multiple senses at once. Instead of just reading text, a multimodal AI can process images, audio, and video all at the same time to get a much richer, more complete picture of what's going on.

Think about learning a new recipe. You probably wouldn't just read the instructions. You might also watch a cooking tutorial to see the technique and listen for the sound of food sizzling in the pan to know it’s cooking right. Each piece of information—or modality—adds a new layer to your understanding.
This is exactly what multimodal learning gives to an AI. An AI that only understands text might process a transcript about a dog barking, but it has no real clue what that sounds or looks like. A multimodal system, on the other hand, can actually connect the words "dog barking" with an audio clip of a bark and a photo of a dog.
Sticking to a single stream of information gives an AI major blind spots. It’s like trying to understand a situation with one eye closed and both ears covered. You only get one piece of the puzzle, and you miss all the important context.
This is exactly why combining data types is such a big deal. It helps AI graduate from a narrow, one-dimensional view to a much more robust and human-like perception of the world.
By mixing different data types, a multimodal AI develops a deeper, more contextual understanding. It’s the difference between reading a sheet of music and actually hearing the full orchestra perform.
To make these ideas a bit more concrete, let's break down the core concepts of multimodal learning compared to the traditional, one-track approach.
| Concept | Simple Explanation | Why It Matters |
|---|---|---|
| Modality | Just a fancy word for a type of data, like text, audio, or an image. | Combining modalities creates a richer understanding than any single one can on its own. |
| Unimodal Learning | AI learning from just one type of data (e.g., text only). | It's limited and lacks real-world context, kind of like reading a book with no pictures. |
| Multimodal Learning | AI learning from multiple data types at the same time. | This approach is way more like how humans learn, allowing for deeper insights and better conclusions. |
| Data Fusion | The techy process of blending information from different modalities. | This is the "how" behind multimodal AI; it’s where the magic of combining data actually happens. |
As you can see, the shift from unimodal to multimodal is all about adding depth and context, moving AI from a specialized tool to a more versatile and intelligent partner.
While the idea of learning from multiple sources isn't exactly new, recent tech breakthroughs have really pushed it into the spotlight. Interest in multimodal AI has been climbing since the mid-90s, but the last few years have seen a massive spike in academic attention.
Between 2021 and 2022 alone, the number of research papers published on the topic jumped from 77 to 106. According to research covered on Nature.com, this surge is partly thanks to better tech and the global shift toward remote learning. This intense focus shows just how crucial this multi-sensory approach is for building smarter AI that can interact with the world in a more meaningful way.

In multimodal learning, data is the main ingredient, and it comes in a lot of different "flavors." To build an AI that truly understands the world, we have to feed it the same kinds of information we use every day. Think of these data types, or modalities, as the AI’s senses.
Let’s take a quick tour of the most common data types that power today’s smartest AI systems. You’ll probably recognize most of them from your daily life, since they're the digital building blocks of how we communicate and experience the world.
These are the big ones, the data types you interact with constantly. They form the foundation of most multimodal systems because they capture so much of how we share information.
While these four are the most common, they're really just the beginning. The magic of multimodal learning comes from its ability to weave in more specialized, and sometimes less obvious, forms of data to get an even clearer picture of reality.
To solve truly complex problems, AI often needs to look beyond standard media. This is where specialized data types come in, giving AI a much deeper, more technical understanding of its environment.
A fantastic example is 3D data. Self-driving cars, like those from Waymo, don't just "see" with cameras. They use LiDAR and other sensors to build a constantly updating 3D map of the world around them. This data gives them a precise spatial awareness that’s impossible to get from a flat 2D image. It's the difference between looking at a photo of a street and having a full, interactive map of it.
By combining traditional sensor data with the extensive world knowledge from large language models, AI systems gain a more nuanced understanding of complex real-world scenarios.
Then you have tabular data, which is basically anything you’d find in a spreadsheet. This includes sales figures, customer records, and scientific measurements. When you combine a patient's medical scan (image) with their lab results (tabular data), an AI can make a much more informed diagnosis.
Finally, there’s a whole universe of sensory data. This category includes info from highly specific sensors, like temperature readings from a weather station, motion data from a smartwatch, or pressure readings from industrial machinery. Each one provides a very precise, measurable piece of the puzzle.
By pulling from this incredible variety of information, a multimodal system becomes far more versatile and context-aware, moving one step closer to a truly comprehensive understanding of the world.
So, how does an AI actually make sense of all this different information at once? It’s not as simple as just throwing text, images, and audio files into a digital blender and hitting "start." There's a surprisingly cool process happening under the hood, and you don’t need a Ph.D. in computer science to get the gist of it.
Let's use an analogy. Think of the AI as a detective working on a complex case. This detective gets a file filled with different kinds of evidence: a witness statement (that's our text), a grainy security camera clip (video), and a recording of a crucial phone call (audio).
No single piece of evidence tells the whole story. The detective's real skill is in pulling the most important details from each one and then weaving them together to figure out what actually happened.
The first thing our AI detective does is something called feature extraction. This is where the model meticulously sifts through each data stream to find the most meaningful bits of information—the clues. It’s a lot like our human detective taking a highlighter to a transcript or circling a face in a photograph.
This step basically translates all the raw data into a compact, numerical language the AI can work with. It's how the model zeroes in on what's important without getting bogged down by useless details.
Here’s a look at the basic workflow for combining these different data types in a multimodal system.
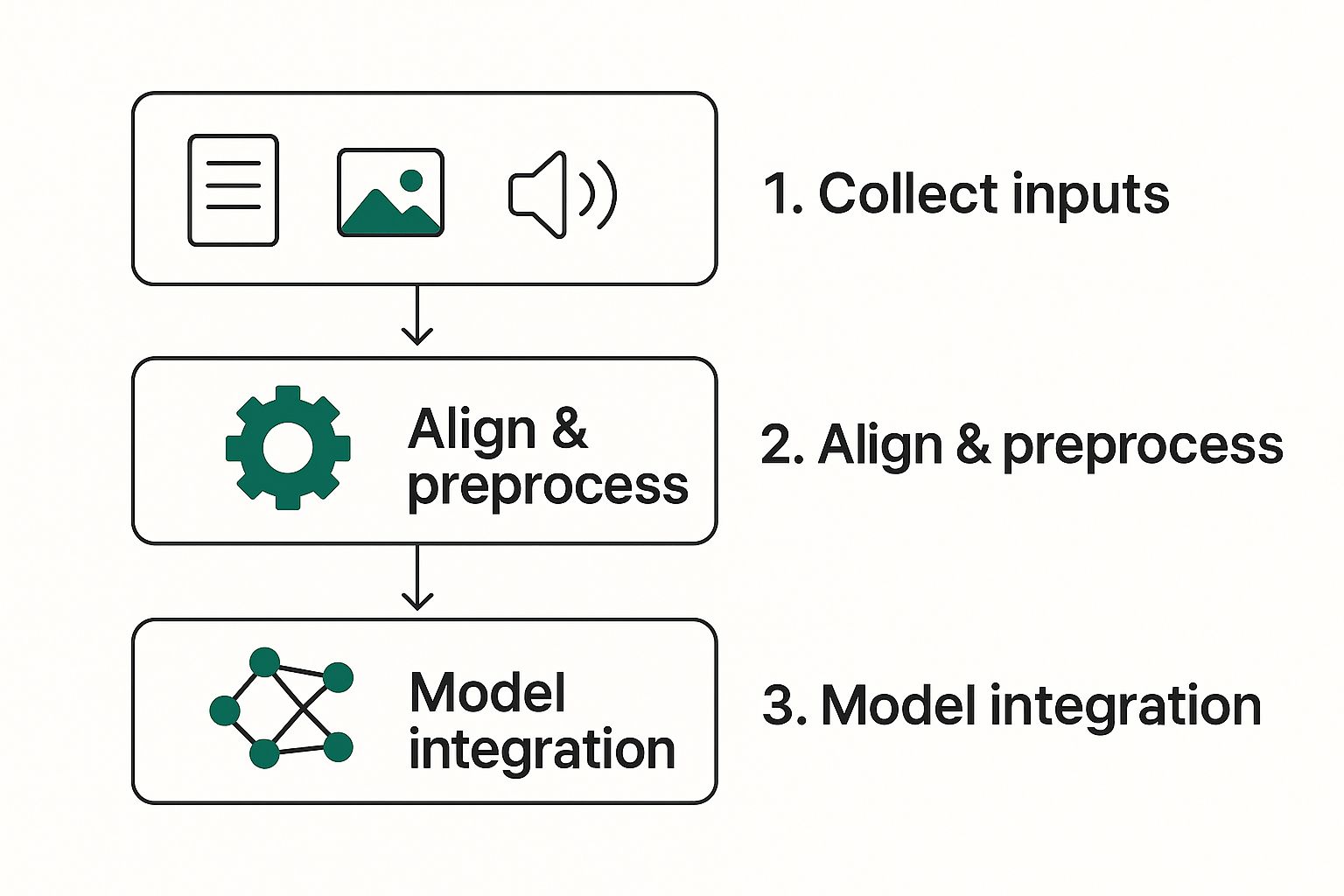
As you can see, the process starts by gathering different inputs, then mashes them together into a single, unified model that can make an intelligent decision.
After the AI has pulled out the key features from each data stream, it's time for the real magic: fusion. This is the art of blending these different pieces of information into a single, coherent picture. This is the moment our detective spreads the highlighted testimony, the important video frames, and the key audio snippets across the desk and starts connecting the dots.
Now, there isn't just one way to do this. AI engineers have a few different strategies for fusing data, and the one they choose depends on what they're trying to do.
The goal of fusion is to create a combined understanding that is far more robust and accurate than what any single modality could provide alone. For example, if a video shows a person smiling but the text says, "I'm so angry," a well-fused model can correctly spot the sarcasm.
The engine driving this whole intricate process is usually a complex architecture known as a neural network. These are algorithms inspired by the human brain that are exceptionally good at finding hidden patterns and relationships in data. If you're curious about the mechanics, you can get a clearer picture by demystifying neural networks in our beginner's guide. Understanding how these networks work really shines a light on what makes multimodal learning so powerful.
All this talk about data fusion and AI detectives can feel a bit abstract. But the truth is, you're already using multimodal learning systems every single day. The concept really clicks when you see it in action, often working quietly behind the scenes to make your favorite apps and gadgets feel so intuitive.
Many of these applications are so well-integrated into our lives that we don’t even notice the complex data blending that makes them possible. From simple conveniences to world-changing technologies, multimodal AI is no longer the stuff of science fiction; it’s a real, practical part of our world.
Your phone is the perfect place to start. Just think about your photo gallery. When you search for "dog," your phone instantly digs up every picture of your furry friend. That’s not magic—it's multimodal learning at its best. The system connects your text input ("dog") with the visual data in your images to understand the request.
The same thing happens with your smart assistant. Ask it, "What does the Eiffel Tower look like?" and it processes your audio command, figures out the question, and then fetches visual results—images and maps—to give you a complete answer. It’s a seamless blend of voice, text, and image data.
Beyond your personal gadgets, multimodal AI is the engine driving some of today's biggest technological leaps, especially in self-driving cars. Autonomous vehicles need an incredibly sophisticated sense of their surroundings, and they get it by processing a constant stream of information from multiple sources at once.
A self-driving car’s system is constantly combining data from:
By fusing all these streams together, the car builds a comprehensive, real-time picture that's far more reliable than what any single sensor could provide. It's this layered perception that allows it to make safe, split-second decisions.
The impact of multimodal learning is also making waves in critical fields like medicine and even the creative arts. In healthcare, AI is changing how doctors diagnose diseases. By analyzing a patient's medical scans (images) alongside their written clinical notes (text) and lab results (tabular data), AI models can spot subtle patterns a human might miss, leading to earlier and more accurate diagnoses.
This technology isn’t just about processing data; it’s about creating a deeper, more contextual understanding that can lead to life-saving insights.
This idea of mixing data types isn't brand new. The roots of multimodal learning trace back to the late 20th century with the rise of multimedia software that combined text, graphics, and audio for education. What started as a way to make learning more engaging has evolved into the complex neural networks we see today. You can get a great overview of this evolution from Deepgram's AI glossary.
On the creative side, you've probably seen the explosion of AI-powered art and video tools. When you give a tool like Midjourney a text prompt—say, "a futuristic city at sunset in a synthwave style"—it translates your text description into a stunning, detailed image. That’s a direct application of multimodal learning, building a bridge between language and visual art.
This same principle is what allows creators to turn written articles into engaging audio, which is completely changing how we learn and consume information. The rise of AI-powered podcasts that are changing education is a perfect example of this in action, making knowledge more accessible than ever.
So, why go to all the trouble of teaching an AI to process different kinds of data at once? The payoff is huge. When you move from a single data stream to a multi-layered approach, you give an AI a much more robust and flexible way to see the world. The benefits aren't just technical—they lead directly to smarter, safer, and more capable tools.
Let's break down the three main advantages that make multimodal learning such a big deal for the future of intelligent systems.
First and foremost, a multi-layered approach leads to a much deeper and more accurate understanding. Think of an AI trying to identify a dog. If it only has an image to work with, it might get confused if the picture is blurry or taken from a weird angle.
But what if that same AI can also hear the sound of a bark and read a caption that says, "Here's a photo of my Golden Retriever"? Suddenly, its confidence skyrockets. Each piece of data backs up the others, correcting potential mistakes and filling in the gaps.
This layered analysis helps eliminate ambiguity and leads to far more reliable conclusions—something that’s absolutely critical for everything from medical diagnostics to self-driving cars.
The world is messy and complicated. We humans rely on context, nuance, and non-verbal cues to communicate, and this is where single-modality AI often falls flat. A text-only model simply can't detect the sarcasm in someone's voice or the real meaning behind a facial expression.
Multimodal systems, however, can. By combining what is said (audio), how it's said (tone), and the body language that goes with it (video), the AI gets the full picture. It can finally begin to understand intent and emotion in a way that feels much more human.
This ability to grasp context is the key to creating AI that can interact with us naturally, from smarter customer service bots to more empathetic digital assistants.
Perhaps the most exciting benefit is that multimodal learning unlocks entirely new possibilities. It's the engine behind the creative AI tools that have captured everyone's imagination.
These creative leaps are only possible because the AI can translate concepts from one modality to another—a skill that has massive implications. For instance, this same technology can help you turn a detailed article into a podcast, making your content accessible to a whole new audience.
The evidence for this multi-sensory approach is compelling. Research synthesizing multiple studies found that students showed significant learning gains when instruction combined visuals with narration or interaction. A review covering nearly 6,000 students confirmed that well-designed multimodal strategies enhance higher-order skills like problem-solving and application. You can explore more about these findings on curriculumredesign.org.
This just goes to show that learning—whether for humans or machines—is simply better when more senses are involved.
To put it all in perspective, let's look at a direct comparison of what AI can do with one sense versus multiple senses.
| Feature | Single-Modality AI (e.g., Text-Only) | Multimodal AI (e.g., Text + Image + Audio) |
|---|---|---|
| Contextual Understanding | Limited to the literal meaning of words; misses sarcasm and emotional cues. | Understands tone, facial expressions, and body language for a complete picture. |
| Accuracy & Reliability | Can be easily fooled by ambiguous or poor-quality data (e.g., a blurry photo). | Cross-references multiple data types to confirm information and reduce errors. |
| Problem-Solving | Solves problems within its own domain (e.g., summarizing an article). | Can connect ideas across different domains (e.g., generating an image from a story). |
| Human Interaction | Interactions can feel robotic and lack nuance, often leading to frustration. | Enables more natural, empathetic, and intuitive conversations with users. |
| Creative Potential | Limited to manipulating a single data type (e.g., rewriting text). | Capable of true cross-modal creation, like generating video from text or music from images. |
As you can see, the jump from single-modality to multimodal isn't just a small step up—it’s a fundamental shift in what AI is capable of achieving.
Still got a few questions? Good. That means you're thinking critically about this. Let's walk through some of the most common questions that pop up when people first start exploring multimodal learning. This should clear up any final fuzzy spots.
We'll cover a few foundational ideas, some practical distinctions, and the real-world hurdles that researchers are working on right now.
Not really, but its recent explosion in capability definitely is. The basic idea of combining different types of data—like text and images—has been around since the early days of multimedia. What’s changed is the sheer power we now have to process it all.
Think of it this way: we’ve always had the ingredients for a complex meal (text, images, audio), but we've only just built an oven powerful enough to cook them together into something truly amazing. Recent breakthroughs in deep learning and computing are that oven. It's why models like GPT-4o have gone from a niche research topic to a technology many of us use daily.
This is a fantastic question, and it's easy to get them mixed up because the names sound so alike. The simplest way to keep them straight is to focus on inputs vs. outputs.
Multimodal learning is about understanding one thing from different types of input data. Think of watching a movie clip and reading its subtitles to understand the scene.
Multi-task learning is about training a model to do several different output jobs from a single type of input. For instance, feeding it a paragraph of text and asking it to both translate it and summarize it.
So, one is about combining senses to get a complete picture, while the other is about being a skilled jack-of-all-trades.
While the potential is enormous, making it work seamlessly is tough. Researchers are constantly bumping up against a few key challenges that make building these complex systems a serious engineering puzzle.
The three main hurdles are:
Solving these problems is what will unlock the next wave of even more capable and intuitive AI.
Ready to put multimodal content to work for your own audience? With podcast-generator.ai, you can instantly turn your written content into engaging, professional-sounding audio. Give your blog posts and reports a voice, and offer your audience a new way to connect with your ideas.
Transform your content into engaging podcasts in seconds with our AI-powered platform.
Get Started Now